

Hemant Bhatt
Writing effective claude.md/agents.md context

A micromanager can turn a simple job into a strangely difficult one.
Give a capable employee a clear task and they will find a sensible way through it. Then the manager arrives: open this file, check that folder, run five commands, use this tool, and follow this exact route.
The employee now has two jobs: solve the problem and perform a small ceremony designed by someone who may not know the best route. That is what a bad AGENTS.md or CLAUDE.md can do to a coding agent.
We create these files with good intentions. We explain the repository, list commands, repeat conventions, and add reminders about tests. The logic feels responsible: more context should produce better work.
But the research paper Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? found a less comforting result. Context files often made coding agents explore more, work longer, and consume more tokens without reliably solving more tasks.
The uncomfortable part
The agents were not ignoring the instructions. They were following them, and sometimes that was the problem.
What Is an AGENTS.md File?
An AGENTS.md file contains repository-level instructions for coding agents. Some tools call it CLAUDE.md, but the idea is the same: it travels with the codebase and gives each agent a little shared project knowledge.
It can explain how to run tests, which build command to use, how the repository is organized, what conventions matter, or which files must not be edited, sparing the team from repeating it in every prompt.
Its real value is the team's memory. An agent cannot remember last Tuesday's strange deployment failure. It cannot know that an innocent-looking folder contains generated code, or that a local service must be running before a test failure means anything. In that sense, AGENTS.md is not supposed to be a tour guide for the whole repository. It is a handover note from the humans who know the project to the agent that is about to work inside it.
Repository context clearly sounds useful. The harder question is whether the files we write actually help agents solve more tasks.
What the Researchers Tested and Found
The researchers tested repository context on real software-engineering tasks. Success meant producing a patch that passed the tests. They used two benchmarks.
SWE-Bench Lite
300 tasks
Issue-resolution tasks from popular Python repositories. These repositories did not have developer-written context files, so the researchers tested generated ones.
AGENTBENCH
138 tasks
Tasks from 12 repositories that already had context files written by their developers.
Four coding-agent setups using Claude Code, Codex, and Qwen Code worked under three context conditions:
| Setting | What the agent received |
|---|---|
| NONE | No repository context file |
| LLM | A generated context file from an LLM or initialization command |
| HUMAN | A context file written and committed by repository developers |
Here were the results:
- No context file was often the best option, or close enough to the best that adding more instructions did not help.
- Human-written context performed better than generated context and sometimes edged past no context, but it still increased agent steps and cost.
- LLM-generated context had the worst trade-off. It slightly lowered success on average while making agents do more work and spend more tokens.
In other words, having no instruction file was often better than adding an autogenerated one. The generated file did not merely fail to help; it also sent a larger token bill.
5 / 8
Settings where generated context reduced performance
+20%
Average cost increase on SWE-Bench Lite
+23%
Average cost increase on AGENTBENCH
Generated context did not destroy performance. It did something subtler: it made the route longer without making arrival more likely. A scenic route is charming on holiday. Less so when tokens are metered.
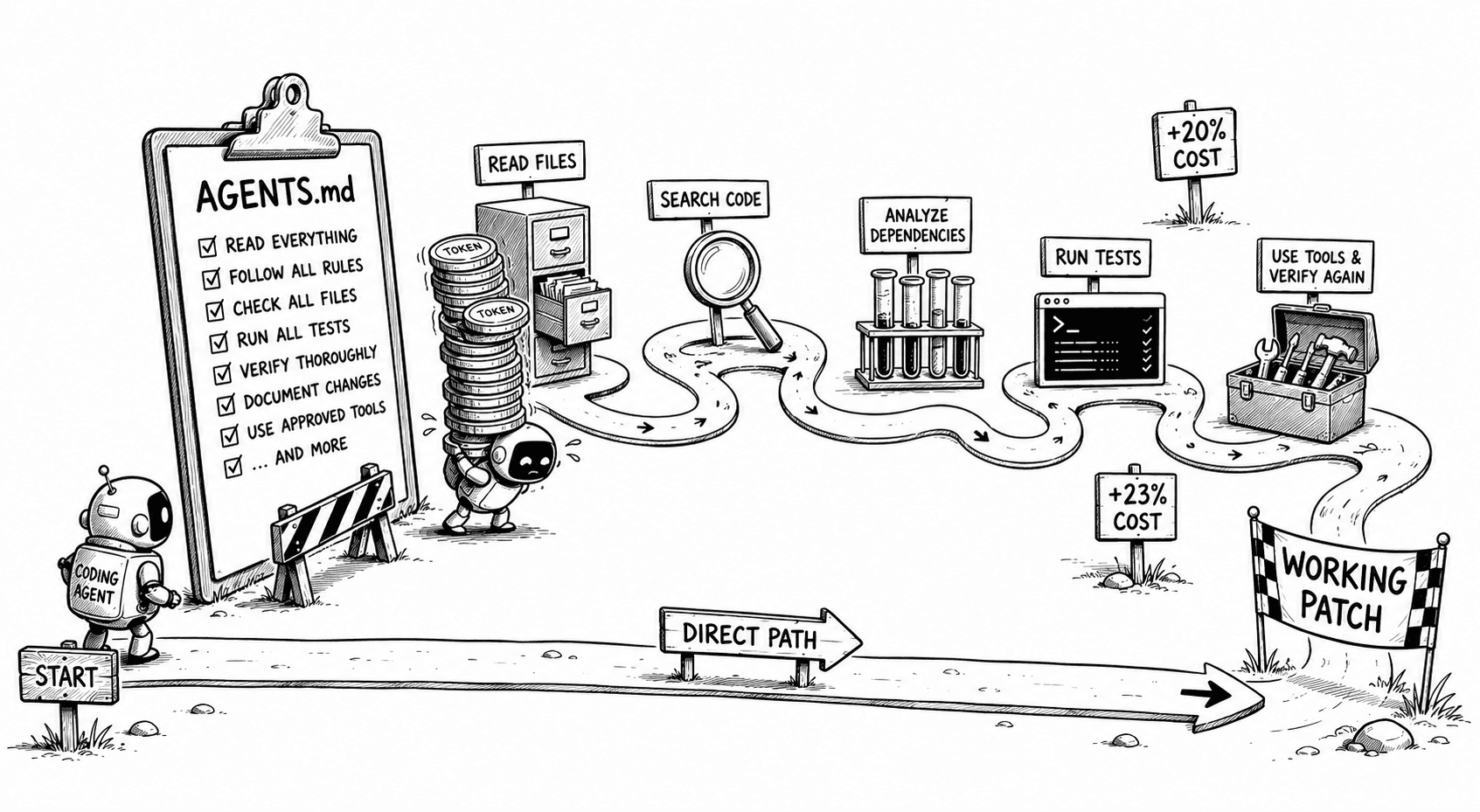
Why Generated Context Struggles
You might assume the agents ignored the files. The study found the opposite.
When a context file mentioned uv, agents used it more often. When a file named repository-specific tools or prescribed broader testing, agents followed along. The instructions changed behavior exactly as instructions should.
So this is not an instruction-following problem; it is an instruction-quality problem. Every permanent rule adds another branch to the agent's reasoning: does this apply now, should I run this command, must I inspect this folder?
A few useful constraints are cheap. A page of obvious ones becomes bureaucracy, leaving the agent to fix your bug while also handling a compliance job.
This was especially visible in generated files, which often summarized information the agent could already discover:
1 src/ contains the source code. 2 tests/ contains the tests. 3 docs/ contains the documentation. 4 Run pytest to execute the tests. 5 Follow the existing code style.
None of this is wrong, but it is not valuable enough to deserve permanent attention. Folder names explain themselves, test commands usually live in configuration or CI, and existing code demonstrates its style.
The real problem is that an autogenerated AGENTS.md often becomes a second README for an agent that can already read the first. Repository overviews did not reliably help agents find the right files faster either. A map that says src contains source code has the confidence of a map and the usefulness of a label on a cupboard.
What Belongs in AGENTS.md
Perhaps a stronger model could generate a better file. The researchers tested that too, but stronger models and different prompts produced no consistent winner.
A capable model can write a cleaner summary. It cannot automatically know which unusual constraint cost your team three hours last month. That is where human-written context has an advantage.
You know translations silently fail in development unless Redis is running. You know preview database connections break when another preview process is alive. You know every user-facing string must pass through a custom translation utility, even when another library looks easier.
These are not repository descriptions. They are the project's scar tissue.
The rule
AGENTS.md should contain only what a smart agent would not discover quickly on its own.
Do not document the visible shape of the repository. Document its hidden edges:
- Non-obvious architectural constraints: generated files, public API boundaries, or dependencies that must remain isolated.
- Repository-specific failure modes: required services, conflicting processes, flaky commands, or misleading errors.
- Efficient validation paths: the fast test command to use first and the conditions that justify a slow suite.
- Decisions invisible in code: compatibility promises, migration rules, security boundaries, or mandatory internal utilities.
- Dangerous operations: data that must not be reset, files that must not be edited, or commands that are unsafe in normal development.
A good context file feels less like onboarding documentation and more like a note from the engineer who knows where the floorboards creak.
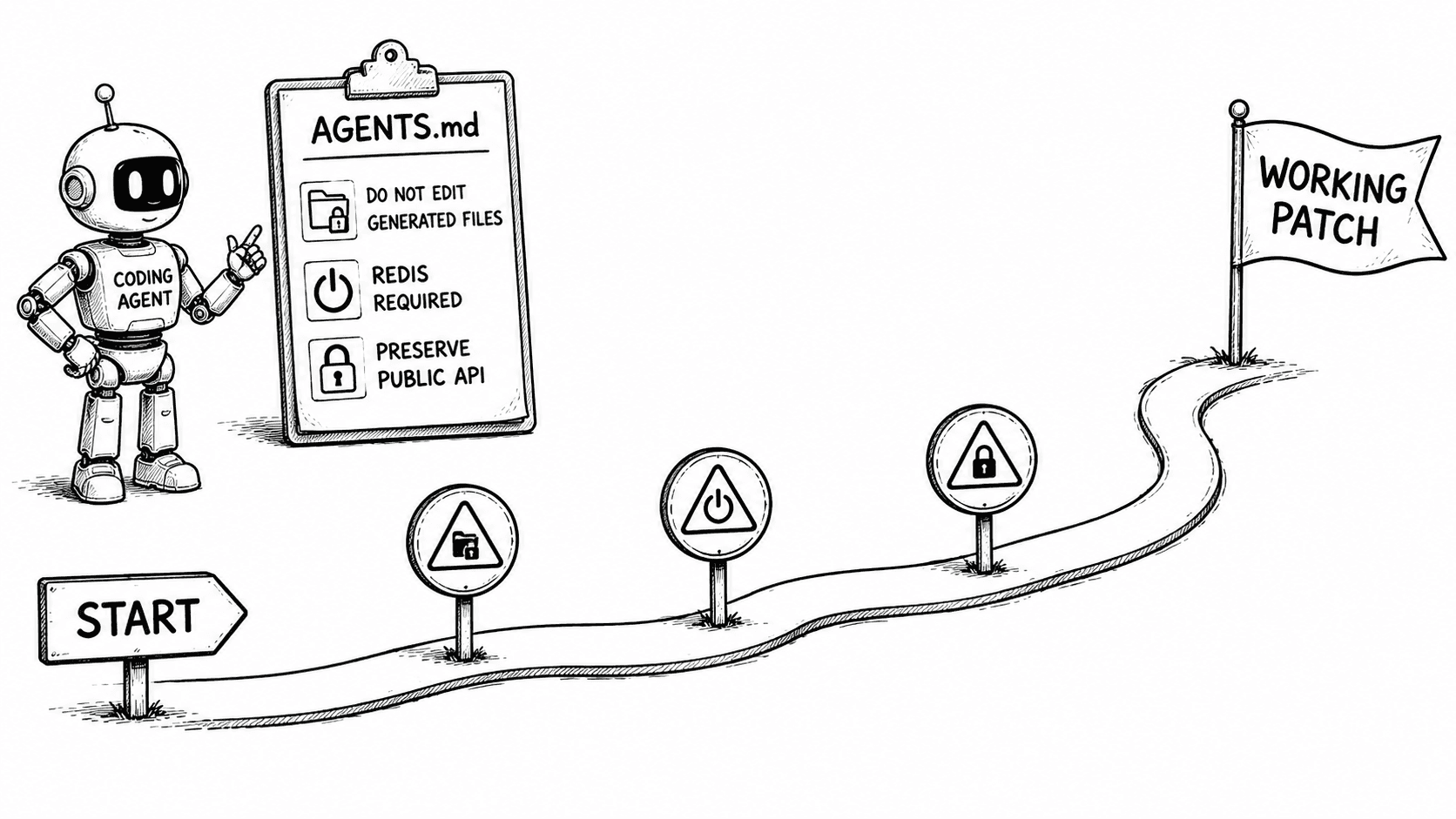
A Bad AGENTS.md and a Better One
The difference is clearest side by side. The first file looks organized, but mostly repeats what the repository already exposes.
The noisy version
1 # Project Overview 2 3 This project contains source code, 4 tests, docs, and examples. 5 6 # Commands 7 8 Run pytest. 9 Run ruff. 10 Run mypy. 11 Run the build. 12 13 # Style 14 15 Follow the existing style. 16 Use clean code. 17 Write tests. 18 Do not break anything.
The useful version
1 # Repository Instructions 2 3 ## Non-obvious constraints 4 5 - User-facing strings must use 6 src/i18n/translate.ts. 7 - Never edit src/generated/. 8 - Preserve exports in 9 src/public-api.ts. 10 11 ## Local development 12 13 - Translation tests require Redis. 14 - Stop an existing preview-db 15 process before debugging 16 connection errors. 17 18 ## Validation 19 20 - Run the focused test first. 21 - Run integration tests only for 22 database, auth, or external APIs.
The noisy version never explains when each command matters. It also asks the agent to write good code, which was presumably already part of the arrangement. "Do not break anything" is especially optimistic. If that worked, software engineering would be a much quieter profession.
Every line in the useful version earns its place. The agent might discover those facts eventually, but the route would be slow or misleading. The file saves work and leaves out the directory tour, generic clean-code advice, command catalogue, and architectural memoir.
The Practical Filter
Before adding a line to AGENTS.md, imagine deleting it. What would happen?
- Is this information non-obvious?
- Is it specific to this repository?
- Would missing it cause a wrong patch or meaningful wasted work?
- Does it apply often enough to deserve permanent context?
- Can it be stated as one clear instruction?
If the agent would recover the same fact within a minute by reading package.json, the line probably does not belong. Keep it when its absence could cause a wrong edit, a broken compatibility promise, twenty minutes debugging a missing service, or an unnecessary integration run.
Permanent context is premium space. Treat it like the top of a kitchen counter: keep the knife you use every day, not every appliance you have ever purchased.
Sometimes no context file is better
There is no prize for having an AGENTS.md. If your repository follows familiar conventions, exposes clear scripts, has accurate documentation, and contains no important hidden constraints, no context file may be the correct choice.
That does not leave the agent without context. The issue, tests, failures, surrounding code, and repository itself are all context. Task-driven discovery is often more focused because the agent reads what the current problem needs. Sometimes the best instruction is room to work.
Conclusion
An AGENTS.md file helps when it behaves like a good technical lead: clear about the dangerous edges and quiet about what the engineer can work out alone. More context does not automatically improve success. Generated files often repeat the repository and increase work; human-written context is strongest when it captures a few non-obvious constraints.
Reference
Thibaud Gloaguen, Niels Mündler, Mark Müller, Veselin Raychev, and Martin Vechev. (2026). Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? arXiv:2602.11988. DOI · Abstract · PDF · CC BY 4.0 license